Figure 1: HANMADANG
Dae-Ki Kang <[email protected]>
Joong-Bae Kim <[email protected]>
Joo-Chan Sohn <[email protected]>
Ho-Sang Ham <[email protected]>
Systems Engineering Research Institute
Korea
This paper describes a World Wide Web (WWW) directory service architecture for Electronic Commerce (EC). We propose a scalable directory service, HANMADANG. The search agent in HANMADANG communicates with other search agents in other databases to make the directory service scalable. HANMADANG has two ways to construct an EC information database. The first way is an indexing assistant agent approach that performs indexing on demand (IOD). The indexing assistant agent is installed on the merchant's system, and can perform indexing immediately on the merchant's demand. The other way is an HTML form approach in which merchants register their information over the WWW browser. When merchants install the agent or register their information, they can specify a period of the indexer's future visit. The dictionaries of HANMADANG are composed of commerce-related documents. In information retrieval systems for EC, it is important for users to find a product with the lowest price. HANMADANG finds the lowest price on the basis of the merchants' registered information. There are three dictionaries for commerce information: Company Identification Code (CIC) dictionary, Product Classification Code (PCC) dictionary, and Chief Function Code (CFC) dictionary. The indexer uses the dictionaries to extract the price information.
Today the World Wide Web[1] (WWW) is a standard tool for communicating information on the Internet. Various types of information can be published on the WWW. HTTP can manage nearly all digital data types including multimedia data. Also, its user-friendly interfaces and open architecture make it popular. Therefore, the Internet has grown rapidly in size and complexity, but too much information makes it difficult for users to find what they really need.
To address this problem, many directory service systems for WWW have been put on the Internet, for example, Yahoo, InfoSeek, Lycos, WebCrawler and so on. Most of them employ both keyword search strategy and content categorizing strategy, and primarily process the English language. In South Korea, there are several directory service systems for WWW also, such as Simmany, Kor-Seek, Kachi-Ne, Wing-Wing-Wing, WAKANO, and so on. Most of them also employ both keyword search strategy and content categorizing strategy. They primarily process the Korean language. For that purpose, their indexing engine processes HTML documents from ".kr" domain. Wing-Wing-Wing can process the English language, too. One big problem of these WWW directory service systems is that their indexers can cause a network bottleneck. Harvest[2] system is a good solution, but it needs a fundamental change in the index storage mechanism. HANMADANG system is not so powerful as Harvest system, but more compatible with the existing technologies.
The Internet has changed people. We begin to realize that the Internet is a "new continent" as a World Wide Marketplace. It is not uncommon to buy goods that are not so expensive over the Internet. As more people want to use the Internet as a new marketplace, they need more electronic commerce technologies. Many merchants have built or are building cybermalls on the Internet, but the existing directory services are not made for cybermalls. So it is a consumer's job to find and organize cybermalls. Some service providers have set up directory services of cybermalls, but they do not support automatic indexing for keyword search.
Our research is about the WWW directory service architecture for Electronic Commerce named HANMADANG. HANMADANG's information indexing strategy is to take an intermediate and hybrid approach over the existing technologies. The purpose of HANMADANG's service is to implement the virtual universal marketplace for supplying the information and knowledge about the commercial products at a reasonable price regardless of the time and space constraints.
Here, we touch on some of the efforts of WWW directory services.
As is stated in the Introduction, there are many general-purpose directory services. Lee and Park's work[3] shows the comparison result among Korean processing WWW directory services with respect to directory services with respect to search engine performance. We also have made a survey on them and present the brief comparison table as Table 1.
| Indexing | Characteristics | Volume | Update | Start Date | |
|---|---|---|---|---|---|
| Wing-Wing-Wing | Signature File | Speed, Portability, Robustness, Multilingual | 1,000,000 pages | one week | March 1996 |
| Simmany | Keyword, Full Text | Keyword Search, Categorizing | 200,000 pages | Keyword: one month Directory: one week | 20 March 1996 |
| Kachi-Ne | Full Text (URL, Title) | Keyword Search, URL Link, Domain Search | 150,000 pages | one month | 10 January 1996 |
| WAKANO | Full Text, Variable Length Coding | Real-time Indexing | 350,000 pages | user's request | 6 September 1996 |
| Kor-Seek | Subject/Word Oriented, Primary Extended | Korean/English, Categorizing | 100,000 pages | one month | 2 December 1995 |
| Zoom | Keyword Search, Boolean Search | Keyword Search, Categorizing | 100,000 pages | one day | 1 November 1996 |
When the indexing database is not distributed, typical WWW directory service systems have network and server bottleneck problems. Harvest system is designed to solve these problems by topology-adaptive index replication, object caching, flexible search engines, and integration mechanisms, but it is not compatible with other existing resource discovery systems. So it would be better to have a way to decrease bottleneck problems without giving up compatibility.
There are so many definitions of agent because there are so many groups that do research on agents, especially the agents on the WWW that have an intelligence for cooperation, user assistance, information retrieval, etc.[4].
There are five types of agent research areas. However, agents are still under research and are not limited to the following five categories.
An agent can be used in information search and retrieval systems where agents navigate around the network to gather information. In HANMADANG, when merchants register their cybermall information, they can install an indexing assistant agent on their site. The indexing assistant agent makes it possible to perform indexing on demand (IOD) of the merchant and to update the index data for a merchant-specified period.
|
Figure 1 is HANMADANG's starting home page for Korean language users. HANMADANG is still at the experimental stage and some parts are still under construction. This service will be publicly available at <http://cals.seri.re.kr/> on 1 March 1998.
Figure 2 shows the architecture of HANMADANG.
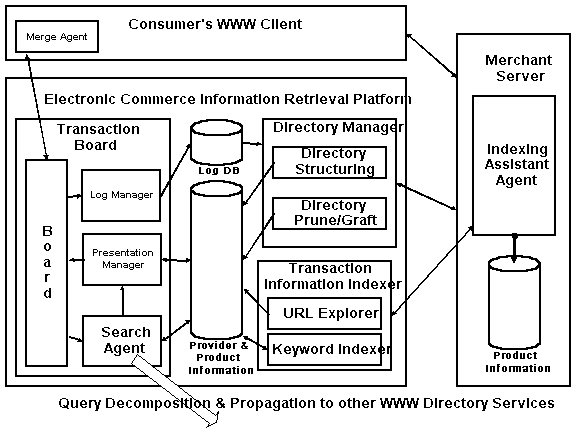 |
Electronic Commerce Information Retrieval Platform is a server system for HANMADANG's directory service. It performs indexing of the information in the WWW space in two ways.
One way is by installing an indexing assistant agent on the merchant's server to set up a time schedule for indexing product information. Then, the HANMADANG server can pull the product information from the merchant's server. The reason for installing the agent on the merchant's server is to avoid the network bottleneck caused by the transaction information indexer in the HANMADANG server. The merchant will specify an index time and an update period of the indexer's visit, so the network and server bottleneck problems can be decreased. After that, the merchant can demand the indexer visit his site immediately through the agent. The indexing assistant agent will notify the transaction information indexer that the merchant server wants to be visited. The transaction information indexer is composed of an URL explorer and a keyword indexer. The URL explorer has charge of getting the next URL, downloading their documents, and sending them to the keyword indexer. The keyword indexer gets the documents, extracts the necessary information including hyperlinks and price information, and sends the hyperlinks back to the URL explorer.
The other way is to get the information by merchants' registration. On the other hand, this way is the merchant server's pushing the product information to the HANMADANG server. The merchant, who wants the Web page to be advertised, runs the Web browser and connects to HANMADANG server, and registers his information by hand. The registration and the future query of information are done by Common Gateway Interface (CGI) application server gateway[5] mechanism.
The search agent in HANMADANG can communicate with homogeneous directory services, which makes the index distribution and directory service scalability possible. We have researched various WWW directory services, and incorporated the intelligence for making queries to some of the heterogeneous search engines and for analyzing the search results. In this case, the search agent is like the existing meta-search engines. If a customer wants to access the HANMADANG server's search service, he can run a WWW browser to the transaction board unit and enter a natural language query. The search agent parses the query sentence to change it into SQL sentences. The translated SQL sentences are executed in the server. The presentation manager is responsible for the user interface and the display of search results. If the result is not satisfactory, the search agent will forward the query and the other factors to the other HANMADNAG servers. HANMADANG's search agent can look for the information in the local and remote databases in that way. We will discuss this more detail in the next section.
Finally, the presentation manager sends the result to the merge agent in the customer's browser. The merge agent is a plug-in program of the browser for merging the search results from the various directory services. The directory manager performs the role of gateway which bridges between Web and database. The directory structuring unit maintains the structure of the directory graph, and the directory prune/graft unit dynamically creates/removes the nodes of the directory structure, if needed. All of the index data will be stored into the provider & product information database. The log manager and the log database are for a user's query history and statistical data.
Figure 3 shows the process flow diagram of HANMADANG's search agent that makes it scalable without burdening the merchant's server.
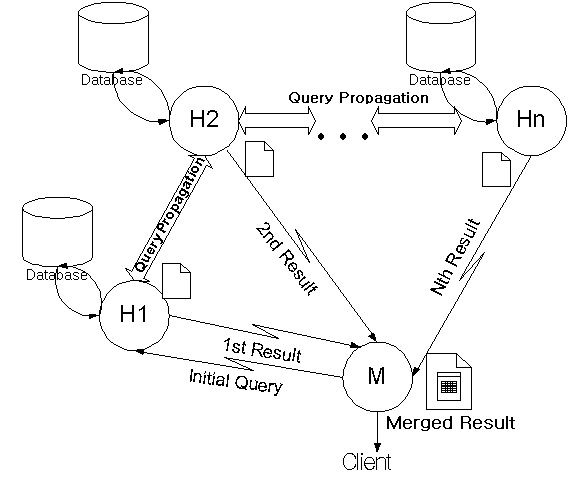 |
Let the number of HANMADANG servers be n. User query is a set of nouns and proper nouns like "Sam-Sung 29 inches TV." When the customer's client in which the merge agent M is plugged browses to HANMADANG search agent #1 (H1) and gives the query and satisfaction threshold t (the number of URLs to find), H1 looks into its local database at first. All databases are specialized for certain products so as to avoid redundancy. When the result is not satisfactory with the threshold, it propagates its query, customer's URL and the modified satisfaction threshold to another HANMADANG search agent H2 and sends the result to M. H2 will do the same job like H1. If the result is satisfactory this time, the entire search flow will stop and H2 will send its own result back to M. If H2's result is not satisfactory and there are no search agents to ask, H2 will send STOP message. Finally, M merges the results from HANMADANG servers over the network. M stops merging when the number of merged URLs is over the satisfaction threshold, and sends them back to the customer's client in HTML form. If M gets STOP message, it will stop merging. Also if there is a time-out, it will stop.
Figure 4 shows the way that HANMADANG works with customers and merchants.
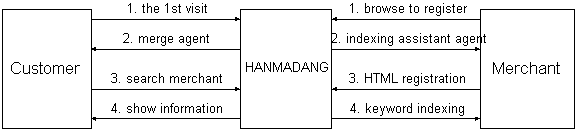 |
The merge agent resides in the customer's client for collecting and reordering the search result from HANMADANG's search agents and the other various search engines. It can be installed automatically with the customers' permission when they register on the HANMADANG directory service. It takes an essential part in the interaction between HANMADANG's indexer and the customers.
The explanation of process flow between the HANMADANG server and the customer is as follows:
The indexing assistant agent is for performing IOD and maintaining the time schedule in the merchant's server. It can be installed automatically with the merchants' permission when they first register on the HANMADANG directory service. When the merchant demands his site to be indexed or updated, the agent notifies the HANMADANG's indexer.
The process flow of how HANMADANG works with cybermalls is described as follows:
The database used for HANMADANG is ORACLE Version 7.3. Figure 5 shows the entity-relation diagram of the HANMADANG database.
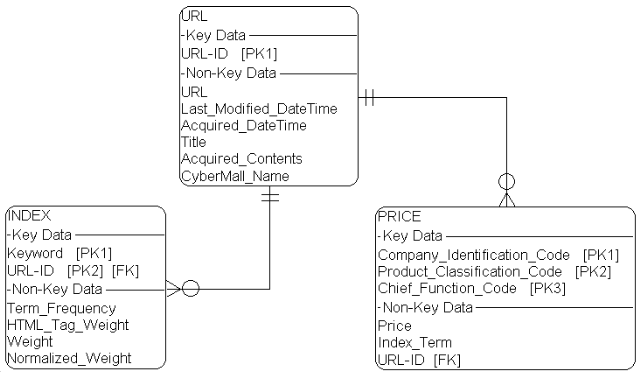 |
There are three main tables in the provider & product information database.
In the URL table, the key field is URL-ID, which is an URL of the indexed document. URL itself is unique, but not suitable for using as a key because of its variable length. Last_Modified_DateTime is a date field for storing the date and the time when the URL document is last modified. Acquired_DateTime is a date field for storing the date and the time when the URL document is first acquired. Title is a <TITLE> tag string. Acquired_Contents is a VARCHAR2 field (unique in ORACLE Version 7.3). The value of this data type is a variable length character string of maximum length 2000. Acquired_Contents is a subset of the document text to which URL-ID points. CyberMall_Name is the name of the cybermall where URL is included.
In the INDEX table, the key fields are Keyword and URL-ID. Keyword is extracted to be used as an index. Term_Frequency is the number of times Keyword shows up in the URL-ID's document. HTML_Tag_Weight is an importance factor of HTML tag with which Keyword text is enclosed. Weight is a weight calculated from Term_Frequency and HTML_Tag_Weight. Normalized_Weight is a normalized value of Weight for ranking.
In the PRICE table, the key fields are Company_Identification_Code, Product_Classification_Code, and Chief_Function_Code. Company_Identification_Code (CIC) is for identifying the company of the product. Product_Classification_Code (PCC) is for the product classification. Chief_Function_Code (CFC) is a code to describe the main function of the product. For example, there can be many kinds of computer monitors from one company, and the Chief_Function_Code can be used to describe the size of computer monitors' CRT. There are dictionaries of CIC, PCC, and CFC in the HANMADANG system. The words in the dictionaries are selected from the commerce-related documents[6, 7] and materials like catalogs, advertisements, newspapers. Price field means a price of the product. Index_Term is a brand name of the product. URL_ID points to the URL of the document from which the PRICE table information came.
In figure 5, PK stands for primary key, and FK is foreign key, and the URL table is one-to-N related with the other two tables.
When the price data are entered by merchants' registration, the indexing and retrieval of them is rather simple. In case of automatic indexing of price information, it is dictionaries that are important for the performance. There are three dictionaries for commerce information in HANMADANG. They are Company Identification Code (CIC) dictionary, Product Classification Code (PCC) dictionary, and Chief Function Code (CFC) dictionary. HANMADANG's indexing system is mainly performing indexing in the cybermalls, which are full of price information, and most price information on the web documents have some rules and patterns. So, we have considered those points and have devised the heuristic algorithms for analyzing them.
One of the main obstacles to price information retrieval is that the information can be presented as graphic images on the WWW. Table 2 shows the four types of price information representation. The DESCRIPTION field is the data type of the description of the product. The PRICE field is the data type of the price of the product. The TECHNOLOGY field tells about the technology to be used to recognize the price and the description information of the product.
| DESCRIPTION | PRICE | TECHNOLOGY |
|---|---|---|
| text | text | information retrieval |
| text | image | information retrieval, character image recognition |
| image | text | character image recognition, information retrieval |
| image | image | character image recognition |
For now, we are working on the case where both description and price are text data. The description is made up of CIC, PCC, and CFC. It will be our further work to understand all the cases above.
To index price information when both description and price are text data, there will be so many heuristics, because there are no formal ways in the merchants' description of the product and its price. Moreover, those heuristics should be different when the text is English or Korean.
We have developed a few heuristics for the price information in English and in Korean, and we present one of most common heuristics for the price information in English. The heuristic steps of it are as follows:
The retrieval of the information is relatively simpler than indexing. As mentioned, the user query is like "Sam-Sung 29 inches TV." The search results are listed in an ascending order of price. There are four steps to retrieve the price information from the provider & product information database.
There are many directory services on the WWW today, but few are made for electronic commerce. HANMADANG is primarily made for electronic commerce and will be researched and developed to make progress in electronic commerce. HANMADANG's integrated and hybrid approach for search on distributed databases is to diminish the bottleneck problems in realistic view.
For now, we don't use a broker agent in the HANMADANG's search strategy because there are few broker agents active on the WWW, but we are going to incorporate a broker agent in HANMADANG's search strategy when HANMADANG is in service next year.
For electronic commerce, it is important to decide whether one Web document contains price information or not. So automatic content categorization techniques for electronic commerce should be developed. In HANMADANG, IOD will assure the indexer a bit that the site it performs indexing on is a cybermall and, therefore, full of price information somewhere.
Regarding the price, it is not a good way to think about the price just printed on the product. The price of time and distance for the product to be sent to the customer should also be considered. Those points will be a further research field of our ongoing project.
As for the merge agent, customers will be reluctant to install it because it consumes customers' resources. Some customers are sensitive about security and refuse to install the program they do not know so much about. It is a common problem of many agent systems for now. To solve this, we are searching for a method for dynamic agent creation and removal. It means the agent is created on the fly and is deleted just after it does its job.
The shopping cart problem is one of the serious problems on electronic commerce. HANMADANG system is just for WWW directory service, but our bigger project named HANMART is being started this year to give a global framework for clients, merchants, and brokers. The shopping cart agent and the shopper agent will be designed in HANMART for the shopping cart problems. The shopping cart agent will extend browsers' capability and will take care of history problems in actual shopping situations.